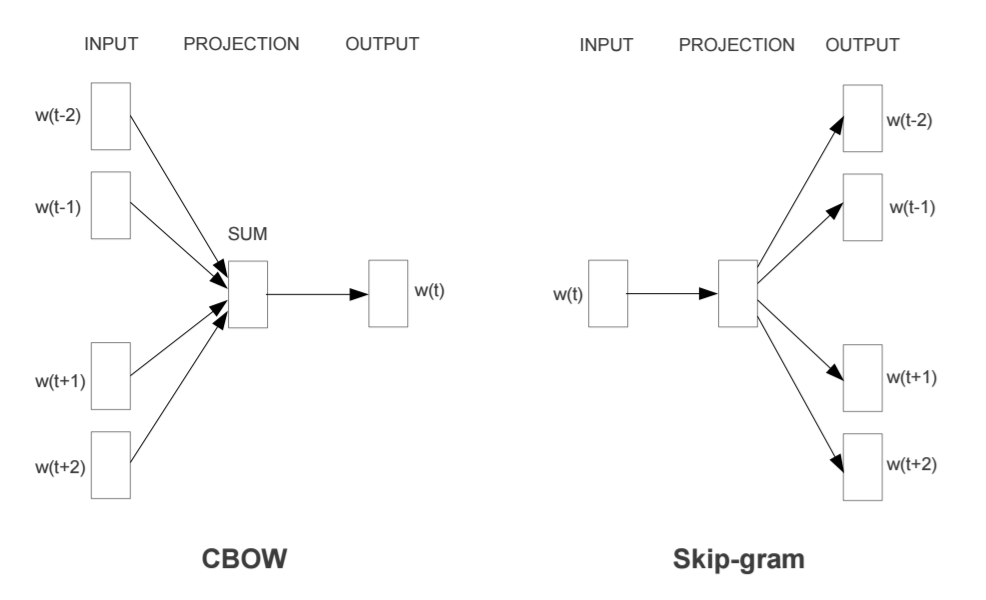
이 글은 이기창 님의 저서인 한국어 임베딩 내용을 라마인드 하기 위해 정리한 문서입니다. https://github.com/ratsgo/embedding/ 3. 한국어 전처리 (p.79~) 3.1 데이터 확보 (p.80~) 3.1.1 한국어 위키백과 (p.80~) 코드 3-1 한국어 위키백과 다운로드 (bash) (p.81) 코드 3-2 한국어 위키백과 전처리 (python) (p.81) 코드 3-4 사용자 정의, 한국어 위키 토크나이저 (python) (p.84) 코드 3-5 한국어 위키백과 전과정 자동 전처리 (bash) (p.85) wikiextractor : 위키백과 정제 라이브러리 https://github.com/attardi/wikiextractor 3.1.2 KorQuAD (p.86~) 한..