이 글은 이기창 님의 저서인 한국어 임베딩 내용을 라마인드 하기 위해 정리한 문서입니다.
https://github.com/ratsgo/embedding/
2. 벡터가 어떻게 의미를 가지고 되는가 (p.57~)
2.1 자언어 계산과 이해 (p.58~)
표 2-1 임베딩을 만드는 세 가지 철학 (p. 58)
| 구분 | 백오브워즈 가정 | 언어 모델 | 분포 가정 |
| 내용 | 어떤 단어가 (많이) 쓰였는가 | 단어가 어떤 순서로 쓰였는가 | 어떤 단어가 같이 쓰였는가 |
| 대표 통계량 | TF-IDF | - | PMI |
| 대표 모델 | Deep Averaging Network | ELMo, GPT | Word2Vec |
백오브워즈(Bag of Words) 가정
어떤 단어가 많이 쓰였는지 정보를 중시
단어의 순서(order) 정보는 무시함
언어 모델(Language Model)
단어의 등장 순서를 학습해 주어진 단어 시쿼스가 얼마나 자연스러운지 확률을 부여
분포 가정(Distributional Hypothesis)
문장에서 어떤 단어가 가팅 쓰였는지를 중요하게 따짐
단어의 의미는 그 주변 문맥(Context)을 통해 유추해볼 수 있다고 봄
분포 가정의 대표 통계량은 점별 상호 정보량(PMI; Pointwise Mutual Information)
2.2 어떤 단어가 많이 쓰였는가
2.2.1 백오브워즈 가정
백(Bag)이란 중복 원소를 허용하는 집합(Multiset)이며 원소 순서는 미고려함
정보 검색(Information Retrieval) 분야에서 여전히 많이 쓰임. 사용자의 질의(Query)에 가장 적절한 문서를 보여줄 때 질의를 백오브워즈 임베딩으로 변환하고 질의와 검색 대상 문서 임베딩 간 코사인 유사도를 구해 유사도가 가장 높은 문서를 사용자에게 노출함
2.2.2 TF-IDF
앞서 단어 빈도 또는 등장 여부를 그대로 임베딩으로 사용 시 해당 단어가 문서의 주제를 가늠하기 어려운 경우가 존재하는 문제가 발생함. 예를 들어 '을/를', '이/가' 같은 경우임. TF-IDF는 이를 보완한 기법임
TF(Term Frequency)는 어떤 단어가 특정 문서에서 얼마나 많이 쓰였는지 빈도
DF(Document Frequency)는 특정 단어가 나타난 문서의 수
IDF(Inverse Document Frequency)는 전체 문서 수(N)를 해당 단어의 DF로 나눈 뒤 로그를 취한 값. 그 값이 클수록 특이한 단어라는 뜻으로 이는 단어의 주제 예측 능력과 직결됨
2.2.3 Deep Averaging Network (p.63~)
문장 내에 어떤 단어가 쓰였는지, 쓰였다면 얼마나 많이 쓰였는지 그 빈도만을 따짐. 문서 분류에 좋은 성능을 보임
2.3 단어가 어떤 순서로 쓰였는가 (p. 64~)
2.3.1 통계 기반 언어 모델 (p.64~)
언어 모델(Language Model)은 단어 시쿼스에 확률(Probability)를 부여(Assing)하는 모델
n-gram이란 n개의 단어를 뜻함
2-gram, bigram : 2단어
3-gram, trigram : 3단어
예를 들어 '내 마음 속에 영원히 기억될 최고의'라는 표현 다음에 '명작이다'라는 다어가 나타날 확률은 조건부확률(Conditional Probability)의 정의를 화룡해 최대우도추정법(Maximum Likelihood Estimation)으로 유도하면 수식 2-2와 같음
수식 2-2 '내 마음 속에 영원히 기억될 최고의' 다음에 '명작이다'가 나타날 확률 (p.66)
P(명작이다 | 내, 마음, 속의, 영원히, 기억될, 최고의)
= Freq(내, 마음, 속의, 영원히, 기억될, 최고의, 명작이다) / Freq(내, 마음, 속의, 영원히, 기억될, 최고의)
Freq는 해당 문자열 시퀀스가 말뭉치에서 나타난 빈도(Frequent)임
하지만 '내 마음 속에 영원히 기억될 최고의 명작이다'라는 빈도가 없는 경우(0인 경우)에는 분자가 0이므로 확률이 0이 됨
이를 해결 하기 위해 n-gram 모델을 사용하여 일부 해결이 가능함
직전 n-1개 단어의 등장 확률로 전체 단어 시퀀스 등장 확률을 근사(Approximation)하는 것. 이는 한 상태(State)의 확률은 그 직전 상태에만 의존한다는 마코프 가정(Markov assumption)에 기반한 것
위 예제를 바이그램 모델로 근사하면 수식 2-3과 같음. 이건 '명작이다' 직전의 1개만 보고 전체 단어 시퀀스 등장 확률을 근사한 것임
수식 2-3 바이그램 근사 예시 (1) (p.66)
P(명작이다 | 내, 마음, 속의, 영원히, 기억될, 최고의) ≈ P(명작이다 | 최고의)
= Freq(최고의, 명작이다) / Freq(최고의)
이어 '내 마음 속에 영원히 기억될 최고의 명작이다'라는 단어 시퀀스가 나타날 확률를 구하기 위해 각 단어를 슬라이딩 해가며 각 확률를 곱하여 계산하는 것이 수식 2-4임. |V|는 어휘 집합에 속한 단어 수를 나타냄
수식 2-4 바이그램 근사 예시 (2) (p.67)
P(명작이다 | 내, 마음, 속의, 영원히, 기억될, 최고의)
≈ P(내) × P(마음 | 내) × P(속에 | 마음) × P(영원히 | 속에) × P(기억될 | 영원히) × P(최고의 | 기억될) × P(명작이다 | 최고의)
= 1309 / |V| * 93 / 1309 * 9 / 172 * 7 / 155 * 7 / 104 * 1 / 29 * 23 / 3503
그러나 데이터에 한 번도 등장하지 않은 n-gram이 존재할 때 예측 단계에서 문제가 발생함. 분자에 각 확률을 곱할 때 0이 계산되어 분자가 0이 됨
이를 위해 백오프(Back-off), 스무딩(Smoothing) 등의 방식이 제안됨
백오프(Back-off)는 n-gram 등장 빈도를 n보다 작은 범위의 단어 시퀀스로 근사하는 방식임. n을 크게 하면 할 수록 등장하지 않는 케이스가 많아질 가능성이 높기 때문임. 예를 들어 앞서 문장은 7-gram에서는 등장 빈도가 0이 됨
N을 4로 줄여서 7-gram 빈도를 근사하면 수식 2-6과 같음
수식 2-6 백오프 기법 예시 (p.68)
Freq(내 마음 속에 영원히 기억될 최고의 명작이다) ≈ α Freq(영원히 기억될 최고의 명작이다) + β
여기서 α, β는 실제 빈도와의 차이를 보정해 주는 파라미터(parameter)임
스무딩(Smoothing)은 수식 2-4(p.65)와 같은 등장 빈도 표에 모두 k만큼 더하는 기법임. 이렇게 되면 '내 마음속에 영원히 기억될 최고의 명작이다)의 빈도는 k(=0+k)가 됨. 이 때문에 Add-k 스무딩이라고도 부름
만약 k가 1인 경우에는 특별히 라플라스 스무딩(Laplace Smoothing)이라고 부름
2.3.2 뉴럴 네트워크 기반 언어 모델 (p.69)
언어 모델 기반을 활용하는 경우 아래 그림 2-5와 같음
그림 2-5 뉴럴 네트워크 기반 언어 모델을 활용한 임베딩 (p.69)
'발 없는 말이' → [언어 모델] → '천리'
주어진 단어 시퀀스를 가지고 다음 단어를 맞추는(Prediction) 과정에서 학습됨
마스크 언어 모델(Masked Language Model)은 언어 모델 기반 기법과 큰 틀에서 유사하지만 디테일에서 차이를 보임
그림 2.6 마스크 언어 모델 기반 임베딩 기법 (p.69)
발 없는 말이 [MASK] 간다 → [언어 모델] → 천리
2.4 어떤 단어가 같이 쓰였는가 (p.70~)
2.4.1 분포 가정 (p.70~)
분포(Distribution) : 특정 범위, 윈도우(Window) 내에 동시에 등장하는 이웃 단어 또는 문맥(Context)의 집합임
분포 가정(Distributional hypothesis)의 전제 : 어떤 단어 쌍(Pair)이 비슷한 문맥 환경에서 자주 등장한다면 그 의미(Meaning) 또한 유사할 것
예를 들어 한국어의 '빨래', '세탁'이라는 단어의 의미를 모른다고 가정했을 때,
'빨래', '세탁' 단어는 타깃 단어(Target Word)이고 두 단어 주변에 등장하는 '청소', '물' 등은 문맥 단어(Context Word)임
타깃 단어 '빨래'의 문맥 단어가 '청소', '요리', '물', '속옷'이 같이 등장하였고,
타깃 단어 '세탁'의 문맥 단어가 '청소', '요리', '물', '옷'이 같이 등장한다면, 분포 가정을 적용해 볼 때
'빨래'와 '세탁'은 비슷한 의미를 지닐 가능성이 높음
또한 '빨래'가 '청소', '요리', '물', '속옷'과 같이 등장하는 경향을 미루어 짐작해 볼 때
이들끼리도 직간접적으로 관계를 지닐 가능성이 높음
2.4.2 분포와 의미 (1) : 형태소
형태소(Morpheme) : 의미를 가지는 최소 단위 (여기서 의미는 어휘적, 문법적 모두 포함)
계열 관계(Paradigmatic Relation) : 해당 형태소 자리에 다른 형태소가 '대치'돼 쓰일 수 있는가를 따지는 것
철수가 밥을 먹는다. → '철수, '밥'은 형태소가 됨, 철수를 나누어 '철', '수'는 형태소가 안됨
'철수' 대신 '영희'가 '밥' 대신 '빵'이 올 수 있음. 이를 근거로 '철수', '밥'에 형태소 자격을 부여함
2.4.3 분포와 의미 (2) : 품사
품사 분류 기준 : 기능(Function), 의미(meaning), 형식(Form)
- 이 샘의 '깊이'가 얼마냐? // '깊이'가 문장의 주어로 쓰임
- 저 산의 '높이'가 얼마냐? // '높이'가 문장의 주어로 쓰임
- 이 샘이 '깊다'. // '깊다'가 문장의 서술어로 쓰임
- 저 산이 '높다'. // '높다'가 문장의 서술어로 쓰임
어휘적 의미로 묶는 경우 : '깊이', '깊다' / '높이', '높다'
형식적 의미로 묶는 경우 : '깊이', '높이' / '깊다', '높다'
하지만 실제 품사를 분류 할 때는 여러 가지 어려움이 따름 (관련 예시는 p.73)
| 체언(명사) | 관형사가 그 앞에 올 수 있고 조사가 그 뒤에 올 수 있음 |
| 용언(동사/형용사) | 부사가 그 앞에 올 수 있고 선어말어미가 그 뒤에 올 수 있고 어말어미가 그 뒤에 와야 함 |
| 관형사 | 명사가 그 뒤에 와야 함 |
| 부사 | 용언, 부사, 절이 그 뒤에 와야 함 |
| 조사 | 체언 뒤에 와야 함 |
| 어미 | 용언 뒤에 와야 함 |
| 감탄사(간투사) | 특별한 결합 제약 없이 즉, 문장 내의 다른 단어와 문법적 관계를 맺지 않고 따로 존재함 |
그림 2-8 한국어 품사 분류의 일반적 기준 (p.74)
2.4.4 점별 상호 정보량
점별 상호 정보량(PMI, Pointwise Mutual Information) : 두 확률변수(Random variable) 사이의 상관성을 계량화 하는 단위
두 확률변수가 완전히 독립(Indepent)인 경우 그 값이 0이 됨
독립은 단어 A가 나타나는 것이 단어 B의 등장할 확률에 전혀 영향을 주지 않는 것. 그 반대도 포함
PMI (A, B) = log( P(A,B) / P(A) × P(B) )
수식 2-7 점별 상호 정보량(PMI) (p.75)
점별 상호 정보량은 분포 가정에 따른 단어 가중치 할당 기법임. 두 단어가 얼마나 자주 같이 등장하는지에 관한 정보
해당 단어의 임베딩으로 사용 가능
예시) 개울가에서 속옷 빨래를 하는 남녀
형태소 : '개울가', '에서', '속옷', '빨래', '를', '하는', '남녀
Window가 2인 단어-문맥 행렬 생성
빨래 기준 일 때 : '개울가', '에서', '속옷', '빨래', '를', '하는', '남녀
| 단어\문맥 | 개울가 | 에서 | 속옷 | 빨래 | 를 | 하는 | 남며 | Total |
| 개울가 | ||||||||
| … | ||||||||
| 빨래 | +1 | +1 | +1 | +1 | 20 | |||
| … | ||||||||
| Total | 15 | 1000 |
그림 2-9 단어-문맥 행렬 구축 (p.75)
위와 같이 단어-문맥 행렬릉 모두 구했을 때, 빨래-속옷 간의 PMI를 계산하면 수식 2-8과 같음
전체 빈도 수 : 1000회
단어'빨래' 등장 횟수 : 20회 (행)
문맥'속옷' 등장 획수 : 15회 (열)
PMI ('빨래', '속옷') = log ( P('빨래', '속옷') / P('빨래') × P('속옷') )
= log ( (10/1000) / (20/1000) × (15/1000)
구식 2-8 빨래-속옷의 PMI 계산 (p.76)
2.4.5 Word2Vec (p.76~)
분포 가정의 대표적인 모델은 2013년 구글 연구팀이 발표한 Word2Vec이라는 임베딩 기법임
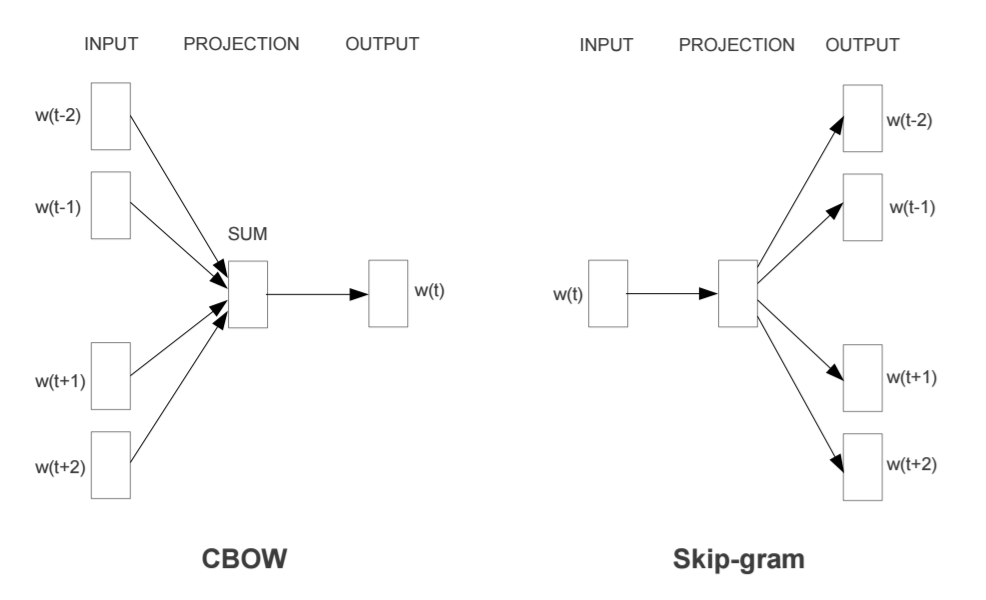
CBOW(Continuous Bag of Word) 모델은 문맥 단어들을 가지고 타깃 단어 하나를 맞추는 과정에서 학습
예를 들면 '점심을 먹지 않아서 _가 고프다' 라는 문장에서 '배'라는 단어가 없어도 주면 문장을 통해 '배'를 유추할 수 있는 것임. 즉 주변 단어를 통해 중심 단어 예측
Skip-gram 모델은 타깃 단어를 가지고문맥 단어가 무엇일지 예측하는 과정에서 학습 (CBOW와 반대)
예를 들면 '___ __ ___ 배가 ___'라는 중심 단어를 통해 주변 단어인 '점심을 먹지 않아서 __ 고프다'라는 단어를 예측
Word2Vec 기법은 PMI 행렬과 깊은 연관이 있음 (논문으로 발표됨)
2.5 이 장의 요약 (p.77~)
- 임베딩에 자연어의 통계적 패턴(Statistical Pattern)정보를 주면 자연어의 의미(Semantic)를 함축할 수 있음
- 백오브워즈 가정에서는 어떤 단어의 등장 여부 혹은 그 빈도 정보를 중시함. 단, 순서 정보는 무시함
- 백오브워즈 가정의 대척점에는 언어 모델이 있음. 언어 모델은 단어의 등장 순서를 학습해 주어진 단어 시퀀스가 얼마나 자연스러운지 확률을 부여함
- 분포 가정에서는 문장에서 어떤 단어가 같이 쓰였는지를 중요하게 따짐
- 백오브워즈 가정, 언어 모델, 분포 가정은 말뭉치의 통계적 패턴을 서로 다른 각도에서 분석하는 것이며 상호 보완적임
'Study' 카테고리의 다른 글
| 한국어 임베딩 - 3.한국어 전처리 (0) | 2019.12.21 |
|---|---|
| 한국어 임베딩 - 1.서론 (0) | 2019.12.14 |